LangChain & LangGraph: LLM Agent 开发框架
概述
LangChain 和 LangGraph 是 LangChain Inc. 推出的两个 Python/JS 框架,用于构建 LLM 驱动的应用。LangChain 解决”怎么把 LLM 和工具串起来”,LangGraph 解决”怎么让这个过程有状态、可分支、可回退”。两者是同一个生态的不同抽象层级——LangGraph 通常构建在 LangChain 之上。
它们是当前最主流的 LLM Agent 应用层框架,适合快速搭建原型和需要复杂流程控制的生产级 Agent。
LangChain
核心抽象
LangChain 提供了三个核心抽象来构建 LLM 应用:
① Chain(链):把多个步骤串联成流水线。最简单的是一个 prompt → LLM → 输出解析器。
1 | from langchain.chains import LLMChain |
早期 LangChain 的核心就是 Chain。但 Chain 的局限很明显——它是线性的、无状态的、不可分支的。
② Tool(工具):让 LLM 可以调用外部函数——搜索、计算、读写文件、执行 shell 命令。工具的定义就是一个带描述的 Python 函数:
1 |
|
③ Agent(智能体):把 LLM、工具、决策循环组合在一起。最经典的模式是 ReAct——LLM 输出”思考→行动→观察→思考→…”的循环:
1 | Thought: 我需要搜索一下这个错误信息 |
定位
LangChain 解决的核心问题是集成——它提供了统一的接口来对接几十种 LLM 提供商、向量数据库、文档加载器、工具。但它不擅长有状态的复杂流程控制。这就是 LangGraph 要解决的问题。
LangGraph
核心模型:图
LangGraph 把 agent 的执行建模为有向图(graph):
1 | Nodes(节点)= 计算步骤(调用 LLM、执行工具、做判断) |
一个典型的 ReAct agent 在 LangGraph 里:
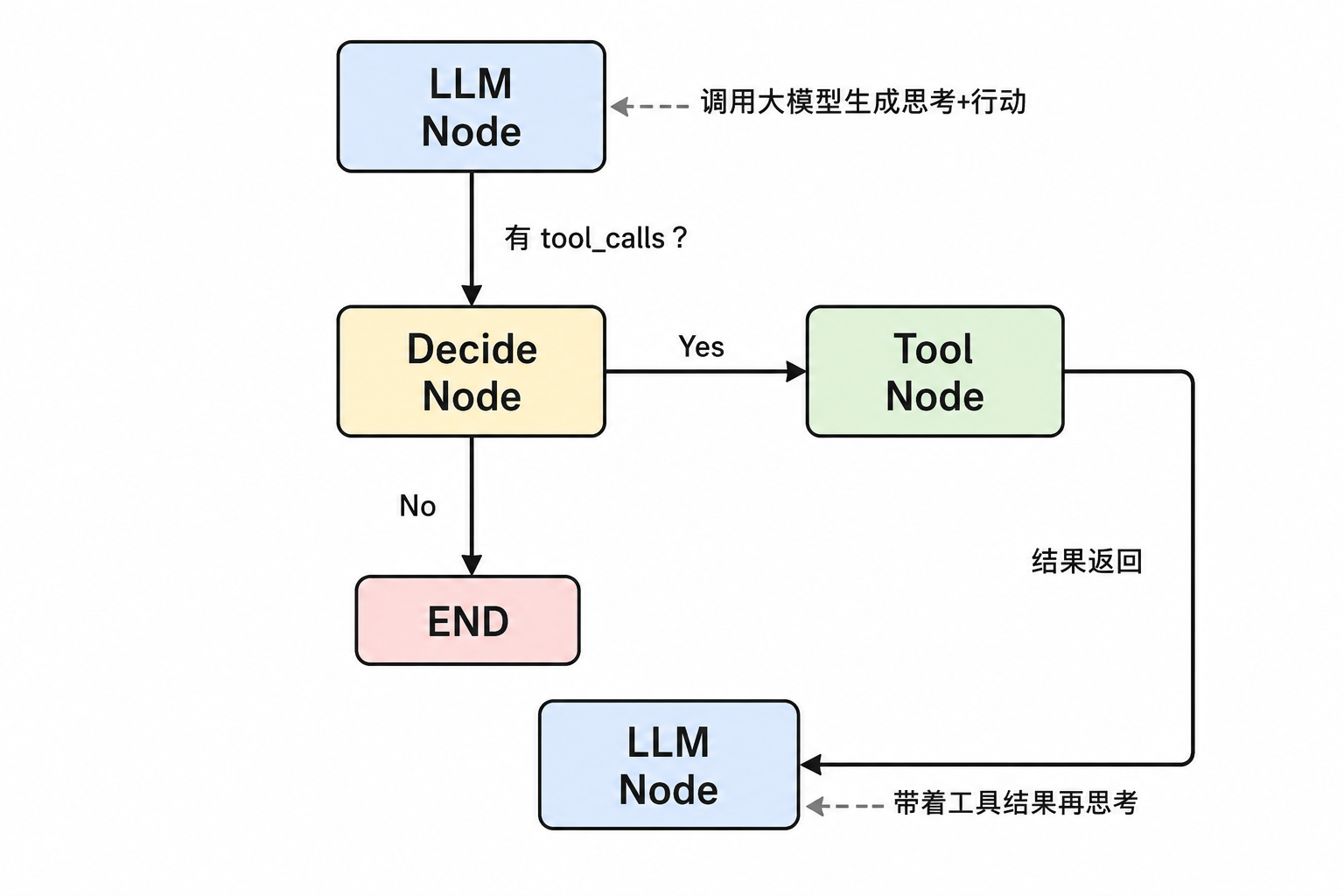
关键特性
① 有状态执行:每个节点读写共享的 state dict,积累对话历史、中间结果、变量。
② 条件分支:边可以是函数——根据 state 的内容决定下一步去哪。
③ 循环:图可以有环(agent 反复思考→行动→思考),传统 Chain 做不到。
④ Human-in-the-loop:可以在任意节点暂停,等待人类审批后再继续。
⑤ 流式输出:每个节点可以 stream 输出 token 级别的增量。
Checkpointer
什么
Checkpointer 是 LangGraph 最重要的内置机制之一。它在每个 super-step 结束后自动保存当前的 graph state。
怎么工作
每个 state 是一个 Python 字典(通常包含 messages 列表、中间变量、元数据)。Checkpointer 负责:
1 | from langgraph.checkpoint.memory import MemorySaver |
支持的存储后端
| 后端 | 持久性 | 适用场景 |
|---|---|---|
| MemorySaver | 进程内,重启即丢 | 开发调试 |
| SqliteSaver | 本地文件 | 单机持久 |
| PostgresSaver | 数据库 | 生产环境 |
| 自定义 | 任意 | 对接自己的存储 |
它存的到底是什么?
一个典型的 checkpoint 内容:
1 | { |
全部是纯 Python 数据结构。没有任何文件系统状态、进程状态、或 OS 级别的任何东西。
三个能力
① 断点续跑:agent 崩溃后从最近的 checkpoint 恢复执行,不需要重跑 LLM 调用。
② Time Travel(时间旅行):可以回退到历史任意一步的 state,从那里重新分枝:
1 | # 回退到 state_1 |
③ 分支(Fork):从同一个历史 checkpoint 出发,用不同 thread_id 分叉出多条轨迹:
1 | fork_config = {"configurable": {"thread_id": "branch-2"}} |
物理局限:Checkpointer 做不到的事
这是 LangGraph 在 AgentFS 知识链中的关键位置——它定义了应用层状态管理的边界。
| Checkpointer 能做到 | Checkpointer 做不到 |
|---|---|
| 保存对话历史 | 恢复被 sed 改过的文件 |
| 保存 Python 变量 | 撤销 pip install 装的包 |
| 记录当前图节点位置 | 恢复被杀掉的后台进程 |
| 序列化 Pydantic models | 恢复被 rm 删除的文件 |
| 时间旅行到历史 state | 让文件系统回到历史时刻 |
具体例子
1 | Turn 1: agent 执行 pip install torch → torch 被安装到 /usr/local/lib/ |
Sources
- LangChain: https://github.com/langchain-ai/langchain
- LangGraph: https://github.com/langchain-ai/langgraph
- LangGraph Persistence Docs: https://docs.langchain.com/oss/python/langgraph/persistence
- 本页为基于 AI 训练知识综合撰写的背景概念解释。
